开源是一种精神,开源是一种境界。在上一个教程中,我们已经一起学习了如何让app说话,根据自己的语音命令执行一个自定义的操作事件,如果你还没有看以上教程,并且之前没弄过安卓app的话,请查看以上教程,不然你会看不懂的哦!
成功弄出语音的创友们,这时会发现,语音命令用的太费劲了,每次说语音命令,都要手动按一下开始按钮,这样的使用体验显然不是我们想要的。如何在开启语音模式后就不需要再按了,直接对着app说语音命令,听完一句就自动执行去,这样多方便呢?是的,我也是这样想的,所以,这次的教程,我们就去改造它,让它开启自动语音模式。
首先,我们先了解一下语音命令的执行周期是怎么样的,简单点说,就是语音命令从什么地方开始的,又在什么地方结束的,机器人给出回应后怎么继续听接下来的语音命令。
我们打开IatDemo.java文件,如下图
打开后我们找到如下图的代码位置
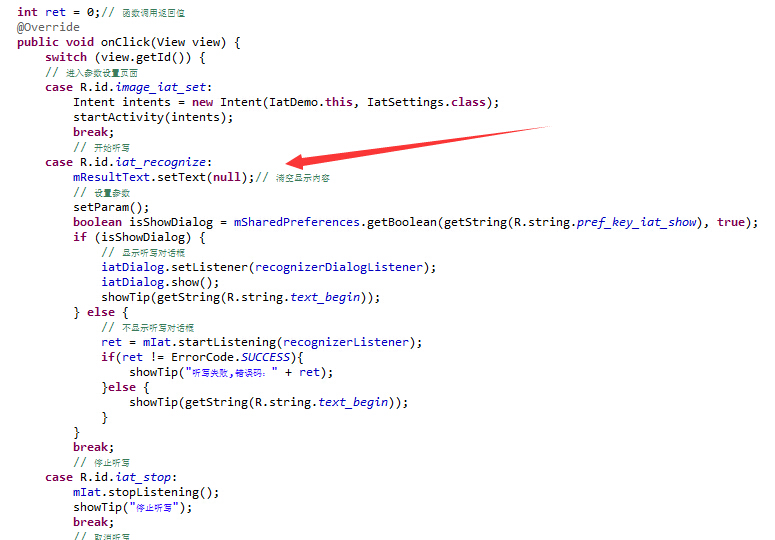
大家可以看到,里面有完整的“开始”按钮,“停止”按钮和“取消”按钮的点击事件,现在是不是找到语音是从哪开始的了吧!我们细看一下,里面么有个recognizerListener如图:
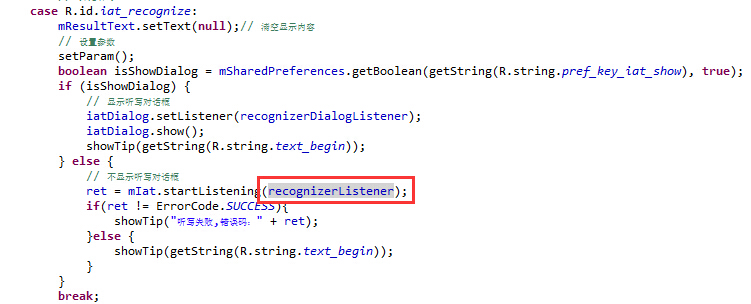
这个是干什么的呢?别着急,我们将鼠标移到上面后,摁住Ctrl键鼠标左击后就自动跳到定义这个东西的地方了,定下心来看看中文注释,是不是有点懂了呢?
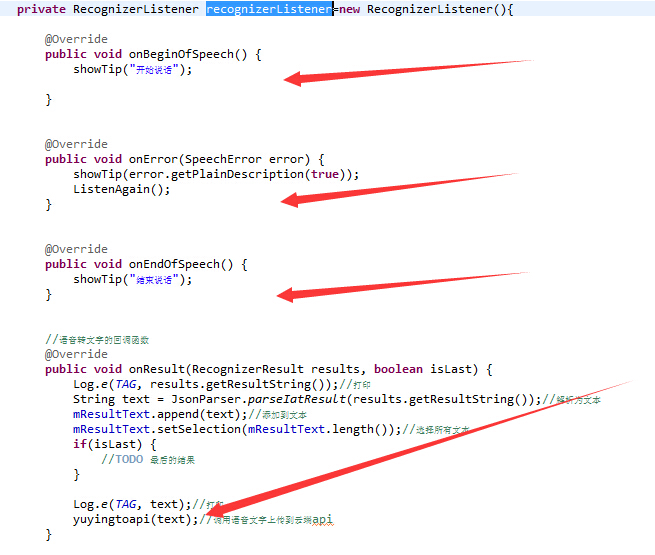
注意红色的箭头,“开始说话”代表语音识别开启,“结束说话”代表语音识别结束,onError表示语音识别存在错误,一般情况下就是开启语音识别,你没说话会导致这个问题,记住它哦,一会我们会用到它。onResult顾名思义,就是得到语音识别结果,怎么去处理它,是不是在里面看到你熟悉的字眼了啊?
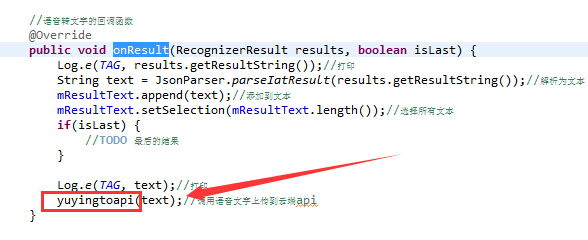
赶紧鼠标移过去,摁住Ctrl然后左击它,这就来到我们上一篇讲解的位置了。至此,我们对语音命令的流程,大致有了一个了解,概括起来就是,打开语音识别->获取到你说的语音后上传到服务器->返回语音识别出来的文字->根据识别出来的文字,判断执行语音命令。
其次,了解了语音识别的流程后,我们先来想一下,怎么去实现自动语音。我的思路是这样的,给app一个开启的关键字符,让它知道你是在叫它,然后打开语音处理开关,听你说了些什么,然后根据你说了什么去执行相关命令,并在最后告诉你:“好的!”“OK!”“卧室灯已关闭!”等等,然后关闭语音处理开关,等待下次你叫它!思路有千变万化,如果你有不同的想法,那最好了,设计属于自己的app是我们共同的目标!在这里我就介绍一下如何实现我的思路吧,如果大家有更好的方案,请在下面留言,我们一起交流学习,大神勿喷!
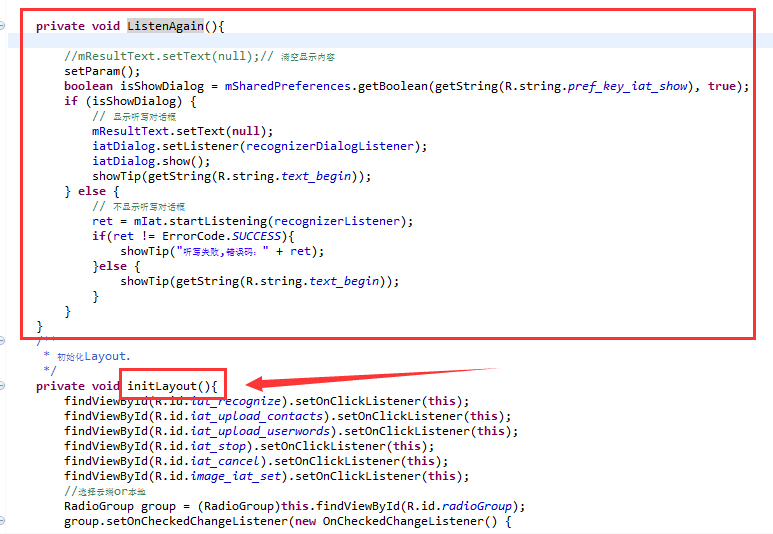
最后,我们一起去实现它吧!第一步,我们在initLayout()的上面粘贴上以下代码
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 | private void ListenAgain(){setParam();boolean isShowDialog = mSharedPreferences.getBoolean(getString(R.string.pref_key_iat_show), true);if (isShowDialog) {// 显示听写对话框mResultText.setText(null);iatDialog.setListener(recognizerDialogListener);iatDialog.show();showTip(getString(R.string.text_begin));} else {// 不显示听写对话框ret = mIat.startListening(recognizerListener);if(ret != ErrorCode.SUCCESS){showTip("听写失败,错误码:" + ret);}else {showTip(getString(R.string.text_begin));}}} |
效果如下图,
这个主要是为了让语言识别在结束后再次启动用的,在什么情况下会用到这个呢?首先,如果开启语音识别,一段时间没有说话,就会关闭识别了,这个时候,我们不能让它关闭,要让它继续识别;其次,如果我们说话了,app处理了我们的命令,并且告诉你:“好的!”“OK!”“卧室灯已关闭!”等等后,再启动重新听,为什么要在结束后开启呢?因为如果不这样,app会把它自己说的话当成语音命令上传,导致卡顿,甚至会出现复读机模式。好了,说了这么多,我们就一步步开始吧!
第一步:在上面的recognizerListener里的onError里添加"ListenAgain();",如下图,这是为了在你开启语音模式后,你没说话的情况下能接着听。
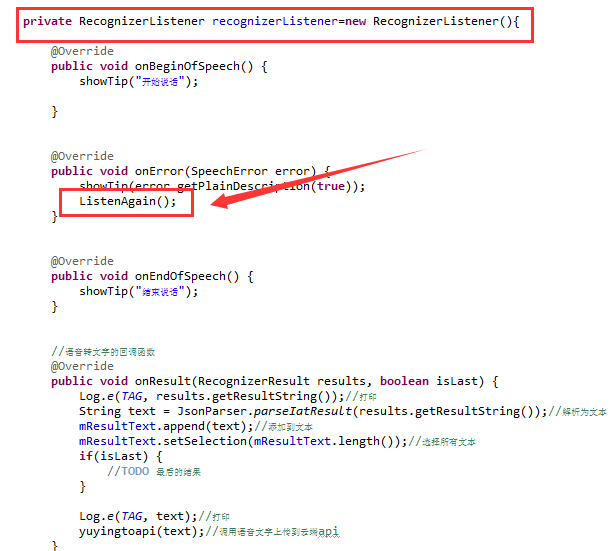
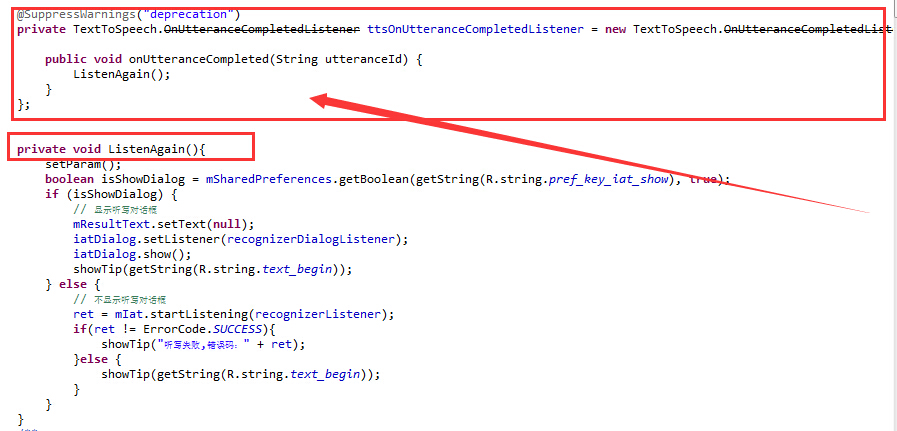
第二步:在ListenAgain上面添加如下代码:
1 2 3 4 5 6 7 | @SuppressWarnings("deprecation")private TextToSpeech.OnUtteranceCompletedListener ttsOnUtteranceCompletedListener = new TextToSpeech.OnUtteranceCompletedListener() { public void onUtteranceCompleted(String utteranceId) { ListenAgain();} }; |
如下图所示:
第三步:在该位置,
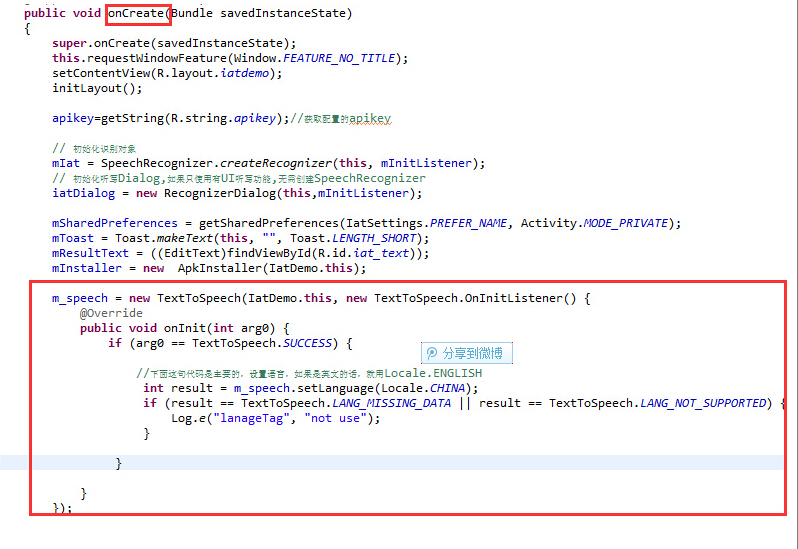
上一教程有提到哦,添加
1 | m_speech.setOnUtteranceCompletedListener(ttsOnUtteranceCompletedListener); |
如图:
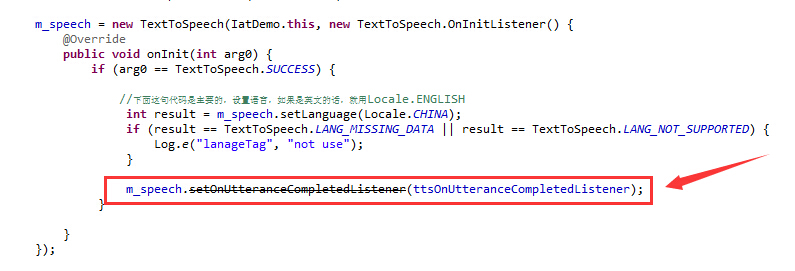
这样,自动语音的运行回路就已经弄好了。
最后一步:我们设置一下那个让app认识的关键字,用来开启识别,怎么弄呢?接着往下。
设置一个全局的开关“boolean mIsAction = false;”,将yuyingtoapi(String yuyin)的东西全部删除,然后粘贴如下代码
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | boolean mIsAction = false;//分析语音批配文字,Post数据到云端服务器api@SuppressWarnings({ "deprecation", "unchecked", "rawtypes" })public void yuyingtoapi(String yuyin) { mIat.stopListening();HashMap myHashAlarm = new HashMap();myHashAlarm.put(TextToSpeech.Engine.KEY_PARAM_UTTERANCE_ID,"end of wakeup message ID");if(yuyin.equals("瓦力")){m_speech.speak("什么事,请您吩咐", TextToSpeech.QUEUE_FLUSH, myHashAlarm);mIsAction = true;return;}if(mIsAction && !yuyin.equals("")){mIsAction = false;//里面可以添加你想要要添加的语音命令} } |
如图:
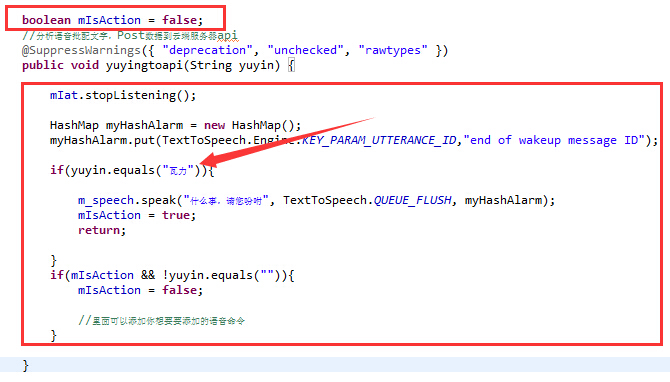
第一个if里面,你可以修改你喜欢的关键字,在第二个if里面,你就可以添加上一个教程里面的语音命令了,特别注意的是添加语音命令有些小变化,下面贴出命令示例
1 2 3 4 5 6 7 | if(yuyin.contains("你好") || yuyin.contains("哈喽") || yuyin.contains("hello")){speakString = "你好!很高兴认识你!";m_speech.speak(speakString, TextToSpeech.QUEUE_FLUSH, myHashAlarm);return;} |
如图,红色框内和上一个教程的变化,上一教程此位置是null,一定要注意修改哦!

至此,我们的自动语音教程就圆满结束了哦,希望大家看了以后,多提宝贵意见,分享你的想法和经验,分享你我,分享快乐!